Seite 1 von 1
Zahlen aus Texten auslesen
Verfasst: Sa 14. Aug 2021, 12:14
von MINTe
Hallo,
ich habe eine Tabelle, in der ich die Verspätungen und Fehlzeiten von meinen SuS (Schülern und Schülerinnen) erfasse. Für jeden SuS gibt es eine eigene Zeile und jede Spalte steht für einen Tag. In der entsprechenden Zelle steht dann eine oder meherere entsprechende Abkürzungen (t - Fehltag, ut - unentschuldigter Fehltag, s - Fehlstunde, us - unentschuldigte Fehlstunde, v - Verspätung). Das Zusammenzählen, wie häufig ein Schüler gefehlt hat bzw. zu spät kam funktioniert so weit. Was mir noch fehlt ist, dass ich die Verspätungszeiten gerne zusammenzählen würde. Ich weiß leider aber nicht wie ich die Zahlen aus dem Text auslesen kann.
Hier ein kleiner Ausschnitt aus der Tabelle. Gewünschtes Ergebnis wäre bei Schüler 2: 3 min und bei Schüler 6: 44 min

Ich würde mich sehr freuen, wenn mir jemand weiterhelfen kann.
Lieben Gruß
MINTe
Re: Zahlen aus Texten auslesen
Verfasst: Sa 14. Aug 2021, 12:45
von Pit Zyclade
Warum machst du nicht pro Tag 2 Spalten?
In der Titelzeile kannst du doch jeweils 2 Zellen verbinden und zentrieren.
Die jeweils 2. Spalte des Tages dient dann ausschließlich dem z.B. Minuteneintrag als Zahl. Dann kann man ganz einfach zusammenaddieren (und ggf. umrechnen...)
Re: Zahlen aus Texten auslesen
Verfasst: Sa 23. Okt 2021, 23:25
von MINTe
Hi Pit,
vielen Dank für deine Antwort. Ich habe das Problem jetzt so gelöst wie du vorgeschlagen hast. Ich hätte es bloß schön gefunden, wenn ich im nachhinein noch gesehen hätte wie lang jede einzelne Verspätung war.
Re: Zahlen aus Texten auslesen
Verfasst: So 24. Okt 2021, 01:17
von Lupp
Wie kann sich Schueluh Nr. 6 am selben Tag zweimal verspaeten?
Was duh in eine Zelle pro Tag und Shueluh anscheinend eintragen willst, wuerde ich "compound data" nennen. Dieses Zeug macht im Allgemeinen nur Probleme. Wenn muh aber aus guten Gruenden ziemlich viele "atomare Daten" in einer Reihe verwaltren will, kommt man gerne auf die Idee, Spalten zu sparen. Die ist zwar nicht gut, aber in LibreOffice Calc gibt es seit Version 6.2 die Funktion REGEX(), mit der muh sich in vielen Faellen aus der Compound-Falle retten kann.
Siehe anhaengendes Beispiel.
Re: Zahlen aus Texten auslesen
Verfasst: So 24. Okt 2021, 13:33
von karolus
Hallo
@Lupp:
Ich kann die RegEx-funktion, derzeit nicht testen, weil ich zurückgewechselt bin zum stabileren 'buster' auf dem RaspBerry (mit LO 6.1.5.2) ,
daher die Frage:
muss der Ausdruck (1)
"(?<=v ?)\d+" so lauten oder geht auch (2)
"v ?(\d+)" oder (3)
"(?:v ?)(\d+)"
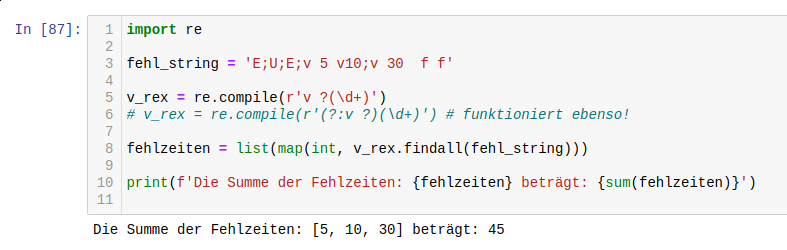
Ich hab die Ausdrücke direkt in Python getestet, dort wirft (1) einen Fehler wegen dem
optionalen Leerzeichen in der Gruppe, die beiden anderen Ausdrücke tun das gewünschte:
- 2021-10-24-13-25-30.png (36.51 KiB) 3553 mal betrachtet
Code: Alles auswählen
import re
fehl_string = 'E;U;E;v 5 v10;v 30 f f'
v_rex = re.compile(r'v ?(\d+)')
# v_rex = re.compile(r'(?:v ?)(\d+)') # funktioniert ebenso!
fehlzeiten = list(map(int, v_rex.findall(fehl_string)))
print(f'Die Summe der Fehlzeiten: {fehlzeiten} beträgt: {sum(fehlzeiten)}')
Re: Zahlen aus Texten auslesen
Verfasst: Mo 25. Okt 2021, 22:49
von Lupp
(Hat ein bisschen gedauert. Musste "mal schnell ein bisschen" Bürokratie machen. Kind hab' ich keines Schlafen gelegt.)
Etwas OT - Regular Expressions im Alltagsgebrauch.
Ich hänge eine neue (teilweise spielerische) Version meiner Beispieldatei an.
Für Kollegen, die unbedingt was über die Frage
lesen wollen, ist Einiges an Text drin.
(Funktionieren PortableApp Packeges -instabilitätsverdächtige Versionen etwa- unter Wine nicht mehr?)
Viel Freude damit!